I am always at a loss to understand why workflow automation is not part of the common operations infrastructure of even the smallest software development shop. Few continuous, autonomous processes can operate without them needing to keep humans informed or occasionally ask them for input. These needs are usually solved by it sending an email to a functional address, eg "clean-the-data@firm.com," containing a short description of the issue and a link to an HTTP enabled form for providing the input. The email is forwarded to the right person, he or she completes it, and the autonomous processes moves forward, sometimes, changing its path. The sent email and the form's use are rarely centrally logged and so the autonomous processes can not be fully audited. Repeat this ad hoc solution for a dozen more conditions and use it a few times per month and you have created post hoc chaos.
We do see some workflow automation tools regularly used in devops groups, but they are specialized. Jenkins, for example, is used to build and distribute applications. Rundeck manages "cron" tasks that need to be executed on all the hosts or services. Even tools like Spiniker is, at heart, a workflow automation. I suspect that all these could be implemented as workflows on top of, for example, Camunda.
Historically, workflow automation has been entwined with ERP and BPM. I don't recall anyone ever saying their company's ERP migration was a pleasure to participate in. (Which reminds me of Douglas Adams's statement that "It can hardly be a coincidence that no language on Earth has ever produced the expression 'as pretty as an airport'.") To discard workflow automation due to the historical horror stories is truly a lost opportunity for the future.
Workflow automation needs to take a more central role in our distributed systems designs. Camunda seems like a good place to begin -- search for talks by Bernd Rücker of Camunda.

Who wants to perpetuate a flawed design when a proper one is just around the corner?
The SimpleDB (SDB) persistence design in Adding persistence to the Incident Response Slack application is poor. The plan was to persist a block of data containing all of a Slack channel's tasks. This SDB item would be named (SDB's primary key) with some combination of Slack channel attributes, such as channel id and enterprise id. I expected to add a version attribute to the SDB item so that I could use SDB's conditional-put to prevent overwriting someone else's changes to the same task list. This all sounds acceptable, but upon further consideration it is not.
Its flaw is that the design focuses on sets of tasks while the UI -- the slash command -- focuses primarily on individual tasks. This flaw led to a design that adds unnecessary contention to task updating. That is, if tasks A and B were being updated at the same time by users X and X, respectively, then it is likely that one of the two updates would fail and have to be retried. Add more concurrency and tasks to the mix then the service will feed unresponsive (pushing users away) and burden the server (increasing operating costs).
Its flaw is that the design focuses on sets of tasks while the UI -- the slash command -- focuses primarily on individual tasks. This flaw led to a design that adds unnecessary contention to task updating. That is, if tasks A and B were being updated at the same time by users X and X, respectively, then it is likely that one of the two updates would fail and have to be retried. Add more concurrency and tasks to the mix then the service will feed unresponsive (pushing users away) and burden the server (increasing operating costs).
The other problem comes from SDB's eventual consistency and how conditional-put will affect throughput. If X and Y are changing tasks then how long will each have to wait on the other before persisting their change? Intuitively, a conditional-put on the version attribute would require that the value be consistent everywhere before a next change. This effectively pipelines all changes to a channel's tasks without any of the advantages a purposefully designed pipeline has.
For this hobby project these flaws are irrelevant. Nevertheless, who wants to perpetuate a flawed design when a proper one is just around the corner?
Internal displacement
When I see these charts I want to know how I can use my skills to help people and not machines.
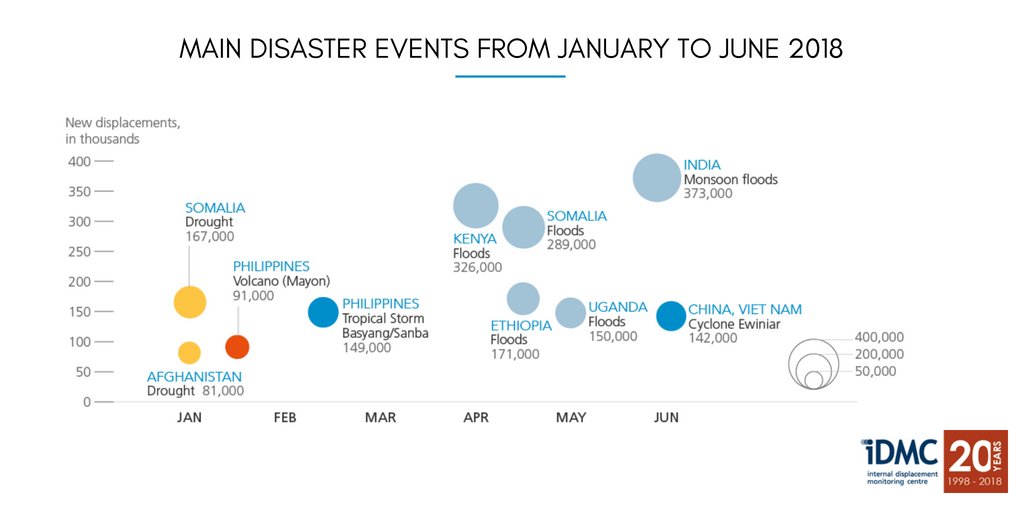
Source http://www.internal-displacement.org/
Source http://www.internal-displacement.org/
What does my pile of tech at Crossref look like?
What does my pile of tech at Crossref look like?
Service infrastructure is 29 deployments -- mostly 4 CPUs and 8G RAM -- handling 100M external (unique) queries and 1B internal requests per month.
Server infrastructure is Tomcat, ActiveMQ, MySql, and Oracle.
Service development is primarily in Java w/ Spring. Infrastructure operations aided with Bash and Perl scripts.
Primary datastores are RDBS using MySql and Oracle.
Secondary datastores are NoSQL using Oracle Berkeley DB, Solr, and bespoke solutions.
Full text search uses Solr, and bespoke Lucene solutions.
Data originates primarily in XML, JSON, tabular, and semi-structured text.
Lots of Linux operations experience. Some AWS operations experience.
No server, disk, or network hardware configuration and operations experience.
Source code managed in Subversion, developed in NetBeans, bespoke CI, and bespoke automated deployments.
Oh, and my trusty MacBook Plus.
Service infrastructure is 29 deployments -- mostly 4 CPUs and 8G RAM -- handling 100M external (unique) queries and 1B internal requests per month.
Server infrastructure is Tomcat, ActiveMQ, MySql, and Oracle.
Service development is primarily in Java w/ Spring. Infrastructure operations aided with Bash and Perl scripts.
Primary datastores are RDBS using MySql and Oracle.
Secondary datastores are NoSQL using Oracle Berkeley DB, Solr, and bespoke solutions.
Full text search uses Solr, and bespoke Lucene solutions.
Data originates primarily in XML, JSON, tabular, and semi-structured text.
Lots of Linux operations experience. Some AWS operations experience.
No server, disk, or network hardware configuration and operations experience.
Source code managed in Subversion, developed in NetBeans, bespoke CI, and bespoke automated deployments.
Oh, and my trusty MacBook Plus.
Equivalence and Equality
There is an interesting debate going on over at The Eternal Issue About Object.hashCode() in Java. The root of the problem in the debate is that the participants are not distinguishing between equivalence and equality (aka identity). In computing we make a distinction between the two. Any two instances are equivalent if their values are the same. Equality is a stronger equivalence. Ie, it is not enough that the values are the same, but the values must be the same instances. Eg, A = "joe", B = "joe", and C = A then A, B, and C are equivalent while only A and C are equal.
Java has made a mess of this distinction because its Object class 1) implements an equals() method and 2) the implementation is equality. So, by default, no two instance are ever equivalent. Most people would consider "joe" and "joe" to be equal, but not Java. (Java should have defined equals() and hashCode() as abstract or, better yet, define them in an Equatable interface.)
My reading of the Eternal Issue article is that there is a contract that base-class instances would use a value, provided during construction, to distinguish themselves. This is equivalence. Eg
Never mix equivalence and equality and an inheritance hierarchy.
A consequence of the rule is that since you decided not to use name to distinguish Baseclass instances then all instances are equivalent. Ie, they are indistinguishable. The only correct change that adheres to the contract would be not to remove equals() but to to replace it with
Java has made a mess of this distinction because its Object class 1) implements an equals() method and 2) the implementation is equality. So, by default, no two instance are ever equivalent. Most people would consider "joe" and "joe" to be equal, but not Java. (Java should have defined equals() and hashCode() as abstract or, better yet, define them in an Equatable interface.)
My reading of the Eternal Issue article is that there is a contract that base-class instances would use a value, provided during construction, to distinguish themselves. This is equivalence. Eg
class Baseclass {
String name;
Baseclass(String name) {
this.name = name;
}
boolean equals(Baseclass that) {
this.name.equals(that.name);
}
}
The sub-class would depend on this, in part, for its determination of equivalence, egclass Subclass extends Baseclass {
int age;
Subclass(String name, int age) {
super(name);
this.age = age;
}
boolean equals(Subclass that) {
super.equals(that) && this.age == that.age;
}
}
Now, what happens when you remove Baseclass's equals() method? Doing that changes Baseclass's distinguishing behavior from equivalence to equality as instances now default to using Object.equals(). This is a extraordinary change to the contract between the classes. Subclass equivalence will immediately start to fail because no two Subclass instances will ever be at the same memory location.Never mix equivalence and equality and an inheritance hierarchy.
A consequence of the rule is that since you decided not to use name to distinguish Baseclass instances then all instances are equivalent. Ie, they are indistinguishable. The only correct change that adheres to the contract would be not to remove equals() but to to replace it with
boolean equals(Baseclass that) { true; }
Of course, any change to Baseclass is likely a bad idea and I would never recommend that you respond to this change with anything less than tar and feathers. But, at least, make sure the changer of the Baseclass understands what they did vis a vis the contract.
Adding persistence to the Incident Response Slack application
Adding persistence to the Incident Response Slack application is the next feature to implement. For this application change happens at a human pace. That is, even the busiest incidence response is unlikely to have more than a few dozen changes per hour. That is, changes per channel per hour. The application might need to coordinate many thousands of channels of changes per hour. Given this situation, persistence at the channel level can be coarse while persistence at the application level needs to be fine.
For coarse persistence with infrequent access storing the whole model as a chunk of data is usually sufficient. Within a channel our model is a collection of tasks each with a description, assignments, and a status. There might be one or two dozen tasks at any time. With an expectation of, on average, short descriptions, one user assignment, and one status we expect 100 to 200 bytes per task and so some 1200 to 4800 bytes in total, ie, 12 tasks * 100 bytes to 24 tasks * 200 bytes. Reading and writing this amount of data is too small to worry about performance; that is, the storage mechanism's overhead will dominate each operation.
For fine persistence with frequent access persisting must be done at the item level. The storage mechanism must allow for random, individually addressable datum. We don't need the storage mechanism to provide structure within the item. A key-value store will do.
A simple system design would have one application instance running on a host that has RAID or SAN storage. If the application crashes the host will automatically restart it and so only incur a second of downtime. And the likelihood of losing the RAID or SAN is too low to worry about. If your level of service allows for this system design then a useful key-value store is the humble file-system. Unfortunately, this design is also the most expensive choice from cloud providers.
Cloud providers will want you to allow them to manage your compute and storage separately. This enables them to provide your application with the highest level of service to your customers. A consequence of this is that your application needs to be designed to run with multiple, interchangeable instances, remote storage, and network partitioning. Unlike the one host & one disk platform, the cloud platforms are not going to help your application that much. The problems associated with distributed application design — CAP, CQRS, consensus, etc — are still largely the application's to solve.
Incident Response is, fortunately, too simple a tool to warrant sophisticated tooling [1]. If two users update the same task at the same time then one of them will win. We will attempt to tell the user of the collision, but the limits of eventual consistency may preclude that. Every cloud platform has a managed key-value store (with eventual consistency) and managed web applications. Since I know AWS, I plan on using SimpleDB and Elastic Beanstalk for the next implementation.
[1] I really want to explore Apache Geode!
For coarse persistence with infrequent access storing the whole model as a chunk of data is usually sufficient. Within a channel our model is a collection of tasks each with a description, assignments, and a status. There might be one or two dozen tasks at any time. With an expectation of, on average, short descriptions, one user assignment, and one status we expect 100 to 200 bytes per task and so some 1200 to 4800 bytes in total, ie, 12 tasks * 100 bytes to 24 tasks * 200 bytes. Reading and writing this amount of data is too small to worry about performance; that is, the storage mechanism's overhead will dominate each operation.
For fine persistence with frequent access persisting must be done at the item level. The storage mechanism must allow for random, individually addressable datum. We don't need the storage mechanism to provide structure within the item. A key-value store will do.
A simple system design would have one application instance running on a host that has RAID or SAN storage. If the application crashes the host will automatically restart it and so only incur a second of downtime. And the likelihood of losing the RAID or SAN is too low to worry about. If your level of service allows for this system design then a useful key-value store is the humble file-system. Unfortunately, this design is also the most expensive choice from cloud providers.
Cloud providers will want you to allow them to manage your compute and storage separately. This enables them to provide your application with the highest level of service to your customers. A consequence of this is that your application needs to be designed to run with multiple, interchangeable instances, remote storage, and network partitioning. Unlike the one host & one disk platform, the cloud platforms are not going to help your application that much. The problems associated with distributed application design — CAP, CQRS, consensus, etc — are still largely the application's to solve.
Incident Response is, fortunately, too simple a tool to warrant sophisticated tooling [1]. If two users update the same task at the same time then one of them will win. We will attempt to tell the user of the collision, but the limits of eventual consistency may preclude that. Every cloud platform has a managed key-value store (with eventual consistency) and managed web applications. Since I know AWS, I plan on using SimpleDB and Elastic Beanstalk for the next implementation.
[1] I really want to explore Apache Geode!
Grumble about the JDK standard libraries
I recently wrote a Slack application and restricted myself to using only the JDK. For some reason, I wanted to reminded myself of how awkward Java programming is for newbies.
No one chooses a Java implementation without the expectation of needing to include a shedload of external libraries. Luckily, Java has the most best of class libraries available, that are easily incorporated with Maven, and that have facilitated the great variety of successful applications being built and maintained every day. The JDK's standard libraries are, however, doddering and incomplete, especially as to building applications for the internet. Scripting languages like Python, PHP, and Ruby do have standard libraries that have evolved to incorporate the internet. And these languages are being successfully used by newbies [1]. Nevertheless, I had my question to answer.
My application uses Slack's outgoing webhooks and so is a specialized HTTP server. The JDK does have an HTTP server, but it is in the com.sun namespace and does not implement the Servlet API. Implementing the Servlet API would give the newbie the experience of using a standard container and, moreover, allow his or her application to be deployed to any number of cloud providers. Implementing an HTTP server is not a quick task and so I choose to use the JDK's.
When Slack sends a webhook request the body content is url form encoded, eg "a=1&b=2&b=3". (You more often see this used in URL queries.) Apart from an early spat over delimiting with ampersands vs semicolons this encoding[2] has been universally, consistently used for decades. Unfortunately, the JDK does not have a standard means to encode or decode this data. I implemented a decoder.
The response to the webhook is a JSON encoded message. JSON's adoption rate has been breakneck, but standard libraries have caught up. The Java Community Process (JCP) did define a JSON API several years ago, but an implementation is not in the JDK. While outputting JSON is straightforward, ensuring it is syntactically correct calls for having support. I implemented an encoder
Lastly, and most sadly, is the situation with fixed width hex values. Slack wants colors expressed in the RGB hex notation, ie #RRGGBB. JDK has a Color class, but it can't be used to create an RGB hex value. (Its Color.toString() method is practically useless.) To format the value you can use
String.format("%02x%02x%02x", c.getRed(), c.getGreen(), c.getBlue())
but, honestly, what newbe is going to know that or have any hope of Googling the answer?
Gumble over. Back to real world Java development.
[1] That academics use Java in introductory programming classes is appalling.
[2] It is not really "encoding" and "decoding," but marshalling and unmarshalling.
No one chooses a Java implementation without the expectation of needing to include a shedload of external libraries. Luckily, Java has the most best of class libraries available, that are easily incorporated with Maven, and that have facilitated the great variety of successful applications being built and maintained every day. The JDK's standard libraries are, however, doddering and incomplete, especially as to building applications for the internet. Scripting languages like Python, PHP, and Ruby do have standard libraries that have evolved to incorporate the internet. And these languages are being successfully used by newbies [1]. Nevertheless, I had my question to answer.
My application uses Slack's outgoing webhooks and so is a specialized HTTP server. The JDK does have an HTTP server, but it is in the com.sun namespace and does not implement the Servlet API. Implementing the Servlet API would give the newbie the experience of using a standard container and, moreover, allow his or her application to be deployed to any number of cloud providers. Implementing an HTTP server is not a quick task and so I choose to use the JDK's.
When Slack sends a webhook request the body content is url form encoded, eg "a=1&b=2&b=3". (You more often see this used in URL queries.) Apart from an early spat over delimiting with ampersands vs semicolons this encoding[2] has been universally, consistently used for decades. Unfortunately, the JDK does not have a standard means to encode or decode this data. I implemented a decoder.
The response to the webhook is a JSON encoded message. JSON's adoption rate has been breakneck, but standard libraries have caught up. The Java Community Process (JCP) did define a JSON API several years ago, but an implementation is not in the JDK. While outputting JSON is straightforward, ensuring it is syntactically correct calls for having support. I implemented an encoder
Lastly, and most sadly, is the situation with fixed width hex values. Slack wants colors expressed in the RGB hex notation, ie #RRGGBB. JDK has a Color class, but it can't be used to create an RGB hex value. (Its Color.toString() method is practically useless.) To format the value you can use
String.format("%02x%02x%02x", c.getRed(), c.getGreen(), c.getBlue())
but, honestly, what newbe is going to know that or have any hope of Googling the answer?
Gumble over. Back to real world Java development.
[1] That academics use Java in introductory programming classes is appalling.
[2] It is not really "encoding" and "decoding," but marshalling and unmarshalling.
I am leaving Crossref
If you would like to talk about coming opportunities then contact me at andrew@andrewgilmartin.com and we will schedule a time to do so.
Incident Response Slack App
As we learn how to better use Slack we are experimenting with different ways of managing our response to incidents, aka emergencies. One experiment is that when an incident is discovered the existing #incident-response channel is used to send an alert to those on-call. We then immediately create a new channel for only the new incident's staffing and communications. While we rarely have overlapping incidents, having a dedicated channel does prevent the interleaving of messages about other incidents, too many tangents, and only those working the incident are disturbed by @channel or @here messages. When the incident is resolved the channel's messages can be copied into the beginnings of the post-mortem document, and then archived.
During the response, tasks emerge that need to be assigned and tracked. Slack itself is not good at this alone. There are many applications for task management that can be made accessible via Slack slash-commands. For incident response tasks, however, these general purpose applications were too focused on the user and not enough on the channel. When listing tasks we only want to see those for this incident. Their extra features also had a cognitive weight that I brisselled at. Overall, their fit for purpose was poor.
What was needed was a task manager with a scope limited to one channel. The task manager would be installed in the workspace, and so accessible to everyone, everywhere without configuration, but when in use was channel focused. The task manager needed to support these simple the use cases
These use cases turned into the /ir slash-command
If you are interested in the implementation then see github.com/andrewgilmartin/com.andrewgilmartin.incidentresponse
During the response, tasks emerge that need to be assigned and tracked. Slack itself is not good at this alone. There are many applications for task management that can be made accessible via Slack slash-commands. For incident response tasks, however, these general purpose applications were too focused on the user and not enough on the channel. When listing tasks we only want to see those for this incident. Their extra features also had a cognitive weight that I brisselled at. Overall, their fit for purpose was poor.
What was needed was a task manager with a scope limited to one channel. The task manager would be installed in the workspace, and so accessible to everyone, everywhere without configuration, but when in use was channel focused. The task manager needed to support these simple the use cases
- Adding tasks with a description, assignments, and a status.
- Updating a task’s description, assignments, or status. Only notify the channel when the changes are pertinent to all.
- Listing the tasks with optional criteria.
These use cases turned into the /ir slash-command
/ir description [ user … ] [ status ]
/ir task-id [ description [ user … ] [ status ]
/ir [ all | finished ] [ user … ] [ status … ]
If you are interested in the implementation then see github.com/andrewgilmartin/com.andrewgilmartin.incidentresponse
Subscribe to:
Posts (Atom)