I have been looking for an "external brain" for many years. I was working at Brown University when tools like Intermedia were being developed and my friends were actively discussing and building Ted Nelson's Xanadu. A consequence is that my standard for these tools is very high.
I am always happy to find a tool that satisfies 90% of my needs and offers a plugin API that someone has created a programatic binding for. Prior to the web, in a time when desktop applications ruled, I learned of Tcl. Years later when wiki's were new I wrote plugins for Jspwiki for server side rendering using Tcl and JavaScript. More recently we have seen the rise of programmable notebooks starting with Jupyter, or, perhaps, earlier with Microsoft Word and Google Docs scripting.
These two threads came together recently as I was exploring Obsidian. Specifically, Obsidian has the Dataview plugin that, more or less, treats the Markdown notes as a queryable and navigable repository. I wanted to use Obsidian to help collect my projects under one interface using a loose GTD approach. Each project is a note and that note lists the project's next action and what it is waiting on as tasks. And there would be a "dashboard" note that automatically enumerates all next actions and waiting ons from all projects.
There are lots of ways of handing this in Obsidian and its plugins -- especially using the Checklist plugin. I think Nicole van der Hoeven's Actually getting things done with Obsidian // Checklist plugin is one of the best. However, I did not like how it was forcing an unnatural encoding and display of next actions and waiting on. Since I am in the exploration phase of learning Obsidian I let my perfectionism override my pragmatism.
A result of the exploration was to use Dataview to achieve my ends. I wanted to encode my project like the following
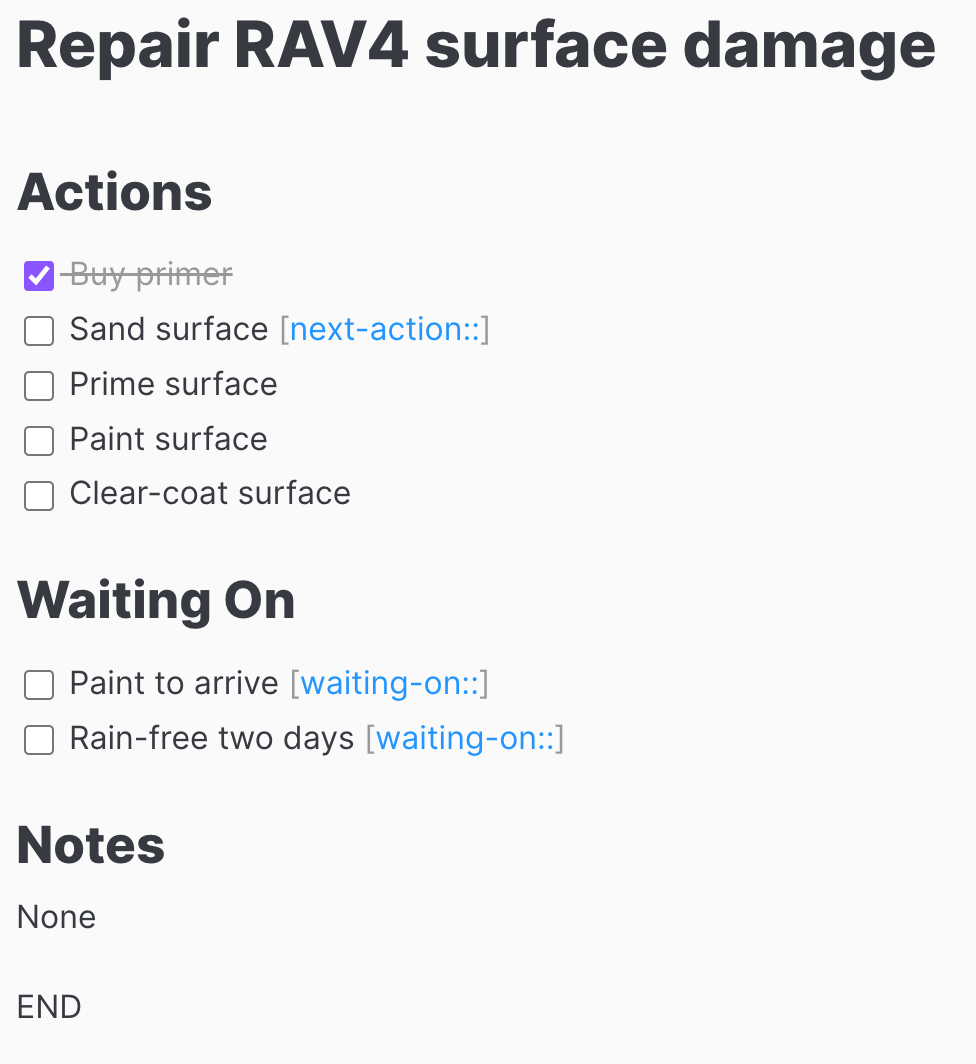
Note the annotation on the next action and waiting on tasks. The dashboard should look like
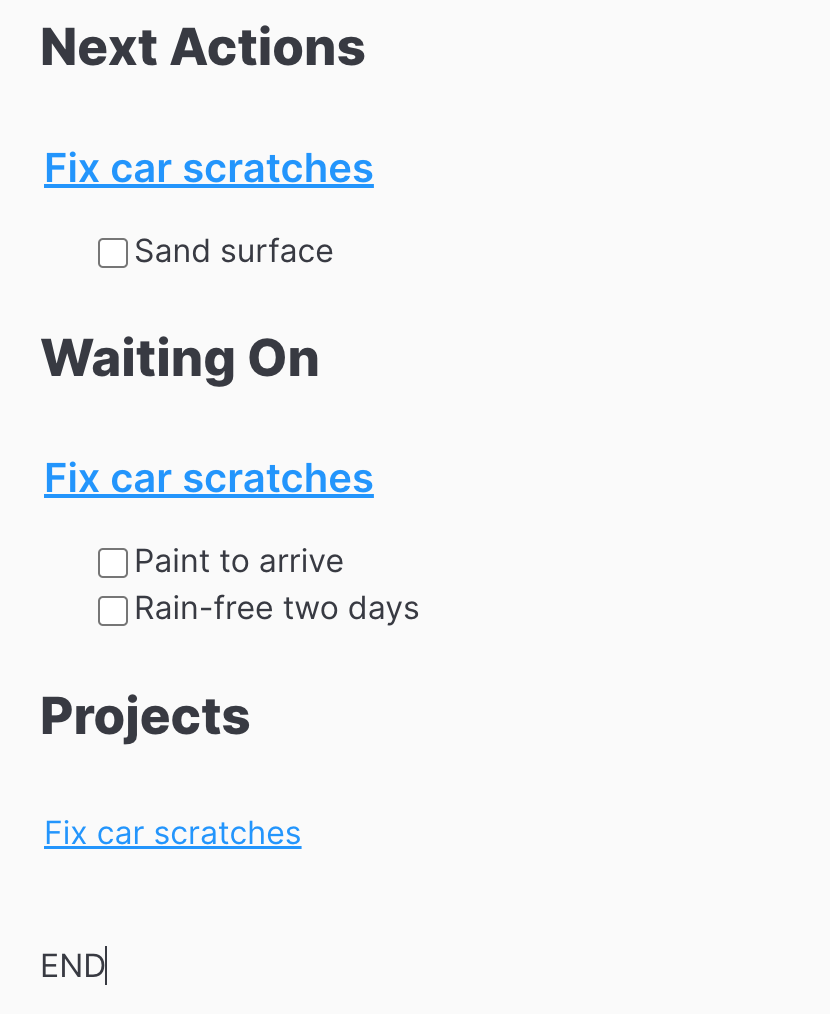
The key feature for this to work is the Dataview annotations it adds to the Obsidian tasks. The annotations are [next-action::] and [waiting-on::]. For the dashboard I can then use the annotations with a Dataview JavaScript code block to select the next actions and waiting ons across projects. Here is the GTD dashboard note
## Next Actions
```dataviewjs
let tasks = dv
.pages('"projects"')
.sort((a,b) => dv.compare(a.file.name, b.file.name))
.file
.tasks
.filter(t => t.annotated && t.hasOwnProperty("next-action"));
if(tasks.length) {
dv.taskList(tasks);
}
else {
dv.paragraph("None")
}
```
## Waiting On
```dataviewjs
let tasks = dv
.pages('"projects"')
.sort((a,b) => dv.compare(a.file.name, b.file.name))
.file
.tasks
.filter( t => t.annotated && t.hasOwnProperty("waiting-on"));
if(tasks.length) {
dv.taskList(tasks);
}
else {
dv.paragraph("None");
}
```
## Projects
```dataviewjs
dv
.pages('"projects"')
.sort((a,b)=>dv.compare(a.file.name,b.file.name))
.forEach(p=>dv.paragraph(p.file.link))
```
END
The end result is
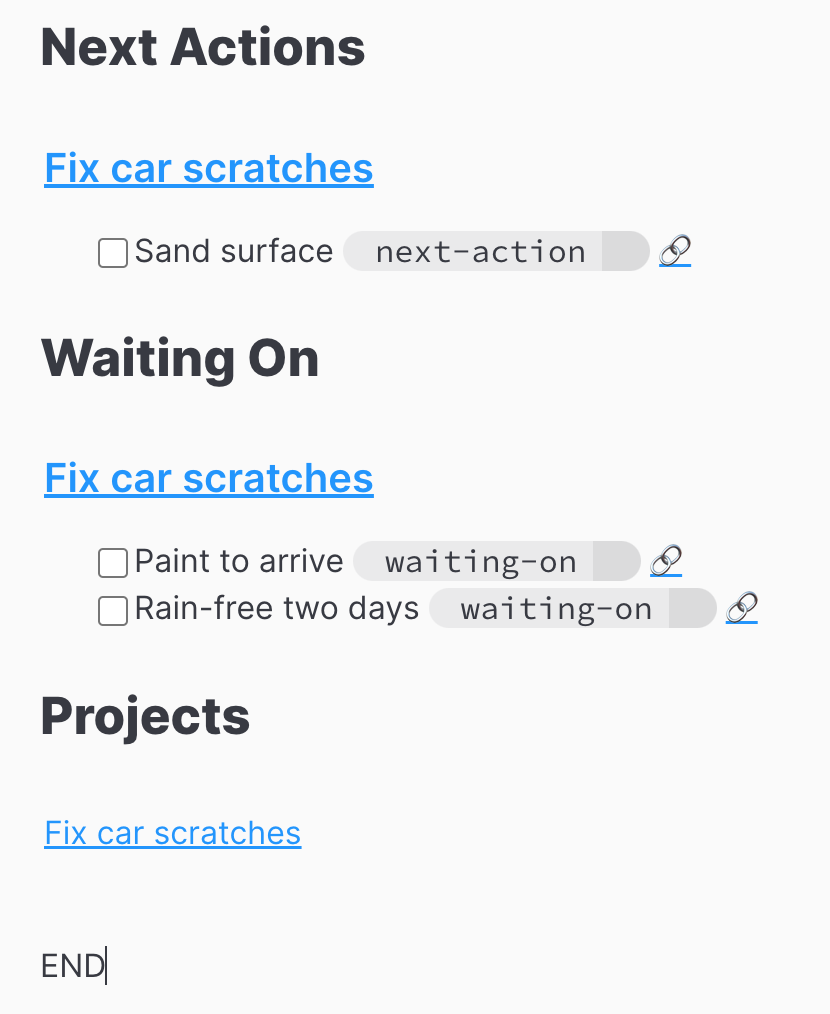
The result is not exactly what I want. I don't want the annotations and the links to be displayed. I have not figured out how to eliminate them yet. It is a good start and I did learn much about Dataview and Obsidian. (Oh, the next step to enhance Dataview or write my own plugin. Maybe not.)


