
I spent several semi-productive hours this weekend writing a plugin for Atlassian's Confluence wiki. The plugin enables the running of JavaScript on the server and placing the result into the page displayed. I have found that using a wiki to intermix static content and dynamic content makes for a great reporting and situation-awareness tool kit (see JSPWiki). I wanted to do the same again within the confines of Confluence 4.x.
Confluence has a really good plugin manager webapp. You can search a repository for existing plugins for immediate inclusion. And you can also upload the plugin from your desktop. I gave the plugin manager a work out getting my plugin to work and can attest to its stability.
And here is the rub, Atlassian has made including and using plugins simple but has made creating a simple plugin almost impossible. My plugin's actual logic is very simple
private static final ScriptEngineManager factory = new ScriptEngineManager();
...
ScriptEngine engine = factory.getEngineByName("JavaScript");
Object result = engine.eval(script);
return result.toString();
Confluence has been around for a long time and I guessed that the pre-Atlas way of building plugins was documented and with code examples. As far as I can tell, and this is after much searching, this is not the case. I was not able to find a single example of a basic plugin built with, for example, Ant. Since, in the end, a plugin is nothing more than a jar containing code and configuration I was shocked that this was missing from the mass of other documentation Atlassian provides. A whole population of, mostly in-house, programmers are being ignored. These are the programmers that are going to build plugins, i.e. small extensions to big tools that aid the better match between Confluence and the users needs.
To this end, here is how I build a basic macro plugin. (Note that the plugin documented here is not what I finally created. In the process of using the JDK's implementation of JavaScript I discovered that it is a old version of Mozilla's Rhino that does not support E4x, the XML language extensions. E4X makes XML a first class data type within JavaScript. Even the JavaScript syntax has been extends to allow for XML constants, for example x = <a/>. And so the final plugin uses Rhino 1.7R3 which does support E4X and JavaScript 1.8.)
The plugin's jar needs a minimum of two files. The Java class and the atlassian-plugin.xml configuration file. The development directory tree is
. ./build.xml ./src/atlassian-plugin.xml ./src/com/andrewgilmartin/confluence/plugins/script/JavaScriptPlugin.java
package com.andrewgilmartin.confluence.plugins.script;
import java.util.Map;
import com.atlassian.renderer.RenderContext;
import com.atlassian.renderer.v2.macro.BaseMacro;
import com.atlassian.renderer.v2.macro.MacroException;
import com.atlassian.renderer.v2.RenderMode;
import javax.script.ScriptEngine;
import javax.script.ScriptEngineManager;
import javax.script.ScriptException;
public class JavaScriptPlugin extends BaseMacro {
private static ScriptEngineManager factory = new ScriptEngineManager();
@Override
public boolean isInline() {
return true;
}
@Override
public boolean hasBody() {
return true;
}
@Override
public RenderMode getBodyRenderMode() {
return RenderMode.COMPATIBILITY_MODE;
}
@Override
public String execute(Map params, String body, RenderContext renderContext) throws MacroException {
try {
ScriptEngine engine = factory.getEngineByName("JavaScript");
engine.put("params", params);
Object evalResult = engine.eval(body);
String result = evalResult.toString();
return result;
}
catch (ScriptException e) {
throw new MacroException(e);
}
}
}
// END
What I have discovered about it is from reviewing Atlassian's own plugins. The atlassian-plugin element's key attribute seems to be a unique identifier but does not have a prescribed structure: I am here just using the JavaScritMacro class's package name. The macro element's name attribute is the name of the macro as used by the user. For example {javascript}1+2+3{javascript}
The build script is
Replace ${env.HOME}/src/confluence-2.10.4-std/confluence/WEB-INF/lib/ with the location of your Confluence jar files.
For more information about building out your plugin do read the documentation and review the code for Atlassian's own plugins, for example Confluence Basic Macros, Confluence Advanced Macros, Confluence Information Macros and Chart Macro.
Atlassian uses the Spring toolkit in their development. Since Spring performs dependency-injection of objects matching the results of using Java reflection to find "bean" names, a lot of Atlassian's code looks like magic is happening. That is, there is no visible configuration or other assignment of object to values and yet the assignments have to made for the code to work. Spring is the magician.
And that is it. The built jar file is a valid Confluence 4.x plugin. Happy wiki scripting
Download an archive of the development tree (Thanks to David Wilkinson for the tool to create this data URI.)
Coda: I was asked why I created my own scripting plugin when two already exist in Atlassian's plugin repository. The initial reason was that our MySql 5.0 installation has too small a max_allowed_packet size and so Confluence was not able to install the existing script plugins into the database. The ultimate reason was that I knew what I wanted from the plugin and said to myself "how hard can it be?"
<atlassian-plugin
name="JavaScript Macro Plugin"
key="com.andrewgilmartin.confluence.plugins.script">
<plugin-info>
<description>A JavaScript macro plugin</description>
<vendor name="Andrew Gilmartin" url="http://www.andrewgilmartin.com" />
<version>1.0</version>
</plugin-info>
<macro
name="javascript"
class="com.andrewgilmartin.confluence.plugins.script.JavaScriptPlugin"
key="com.andrewgilmartin.confluence.plugins.script.javascript">
<description>A JavaScript macro plugin. Place the script to execute within the body of the macro.</description>
</macro>
</atlassian-plugin>
<project name="com.andrewgilmartin.confluence.plugins.script" default="dist">
<property environment="env" />
<path id="build.classpath">
<fileset dir="${env.HOME}/lib/atlassian-confluence-4.3.3/confluence/WEB-INF/lib">
<include name="**/*.jar"/>
</fileset>
<pathelement location="${basedir}"/>
</path>
<target name="dist">
<javac
classpathref="build.classpath"
srcdir="${basedir}/src"
destdir="${basedir}/src"
source="1.5"
target="1.5"/>
<jar
destfile="${basedir}/confluence-plugins-script.jar"
basedir="${basedir}/src"/>
</target>
<target name="clean">
<delete>
<fileset dir="${basedir}" includes="**/*.class"/>
<fileset dir="${basedir}" includes="**/*.jar"/>
</delete>
</target>
</project>
For more information about building out your plugin do read the documentation and review the code for Atlassian's own plugins, for example Confluence Basic Macros, Confluence Advanced Macros, Confluence Information Macros and Chart Macro.
Atlassian uses the Spring toolkit in their development. Since Spring performs dependency-injection of objects matching the results of using Java reflection to find "bean" names, a lot of Atlassian's code looks like magic is happening. That is, there is no visible configuration or other assignment of object to values and yet the assignments have to made for the code to work. Spring is the magician.
And that is it. The built jar file is a valid Confluence 4.x plugin. Happy wiki scripting
Download an archive of the development tree (Thanks to David Wilkinson for the tool to create this data URI.)
Coda: I was asked why I created my own scripting plugin when two already exist in Atlassian's plugin repository. The initial reason was that our MySql 5.0 installation has too small a max_allowed_packet size and so Confluence was not able to install the existing script plugins into the database. The ultimate reason was that I knew what I wanted from the plugin and said to myself "how hard can it be?"


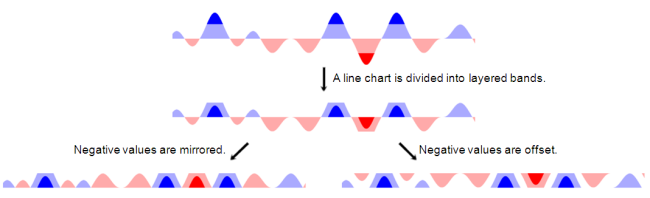 I was a little intimidated by Cubism.js and D3.js; they are sophisticated toolkits that will take more time for me to understand than I wanted to commit just now. Plus I really wanted to learn more about using HTML's canvas element, and so I set about my own implementation.
The code at
I was a little intimidated by Cubism.js and D3.js; they are sophisticated toolkits that will take more time for me to understand than I wanted to commit just now. Plus I really wanted to learn more about using HTML's canvas element, and so I set about my own implementation.
The code at 



